Guide to 'conversational' Backlog management with VS Code / Cursor
Guide to managing and scaling backlog writing in a conversational way with VS Code and Cursor, turning ideas into structured requirements.
| Type | Guide |
| Area | Backlog, Documentation, Tooling |
| Description | Guide to managing and scaling backlog writing in a conversational way with VS Code and Cursor, turning ideas into structured requirements. |
Contents
1. Task to Automate
As a Business Analyst or Product Owner, you are the bridge between ideas and execution. A significant part of your job involves translating discussions, notes, and requirements into well-structured, actionable tickets for the development team.
This guide shows how to turn the manual task of writing tickets into a conversation with an AI assistant using code editors like VS Code with Github Copilot or Cursor.
| Aspect of Work | Manual Process | Automated Process |
|---|---|---|
| Information Gathering | Manually searching through different documents: meeting notes, documentation, backlog | Ask the AI assistant to find relevant information |
| Ticket Drafting | Typing out every section of a requirment from scratch | Provide a high-level idea and let AI Assistant drafts a complete requirment based on a predefined template. |
| Dependency Analysis | Relying on memory or manually searching the backlog or documentation to identify related work. | Ask the AI to analyze provided context and suggest potential functional dependencies. |
| Visualization | Using separate tools to draw flowcharts or sequence diagrams | Create diagrams based on requirement using the diagram as code, in the same tool |
2. Workflow Overview
This workflow centralizes your work in a single application (VS Code or Cursor) and uses an AI assistant as a “conversational partner.” You provide the ideas, context, and direction; the AI handles the heavy lifting of drafting, formatting, and visualizing.
Workflow Steps: A Conversation with Your Backlog
- Describe what needs to be done: Write a rough requirement in natural language
- Add more context: Provide meeting notes, research, or designs to help the AI understand the background (if possible, connect it using MCP)
- Ask for help: If you need more domain knowledge, or quick check what are industry standards, run quick desk research using Perplexity (use MCP, so you don’t have to switch between tools and do copy-paste)
- Find dependencies: Ask the AI which parts of the system could be impacted by this feature. Use your local backlog or connect to it via MCP. You can also include other documents to help the AI spot potential dependencies you might miss.
- Draft the requirement: Let the AI use your input and added context to create a well-structured ticket that follows your team’s format and project standards.
- Visualize and draw diagrams (optional): Describe the user flow or system structure, and let the AI generate a diagram (like a Mermaid chart) to help you and your team better understand it.
- Review and add to backlog: Check the draft, make edits, and push it to your backlog tool.
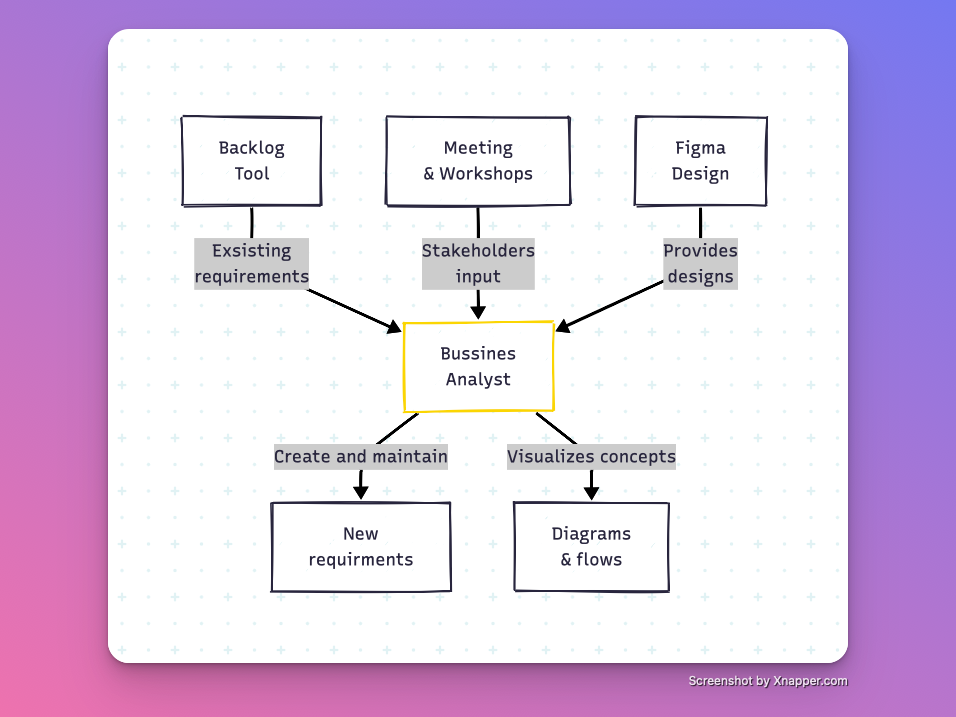
**How we used to do backlog**
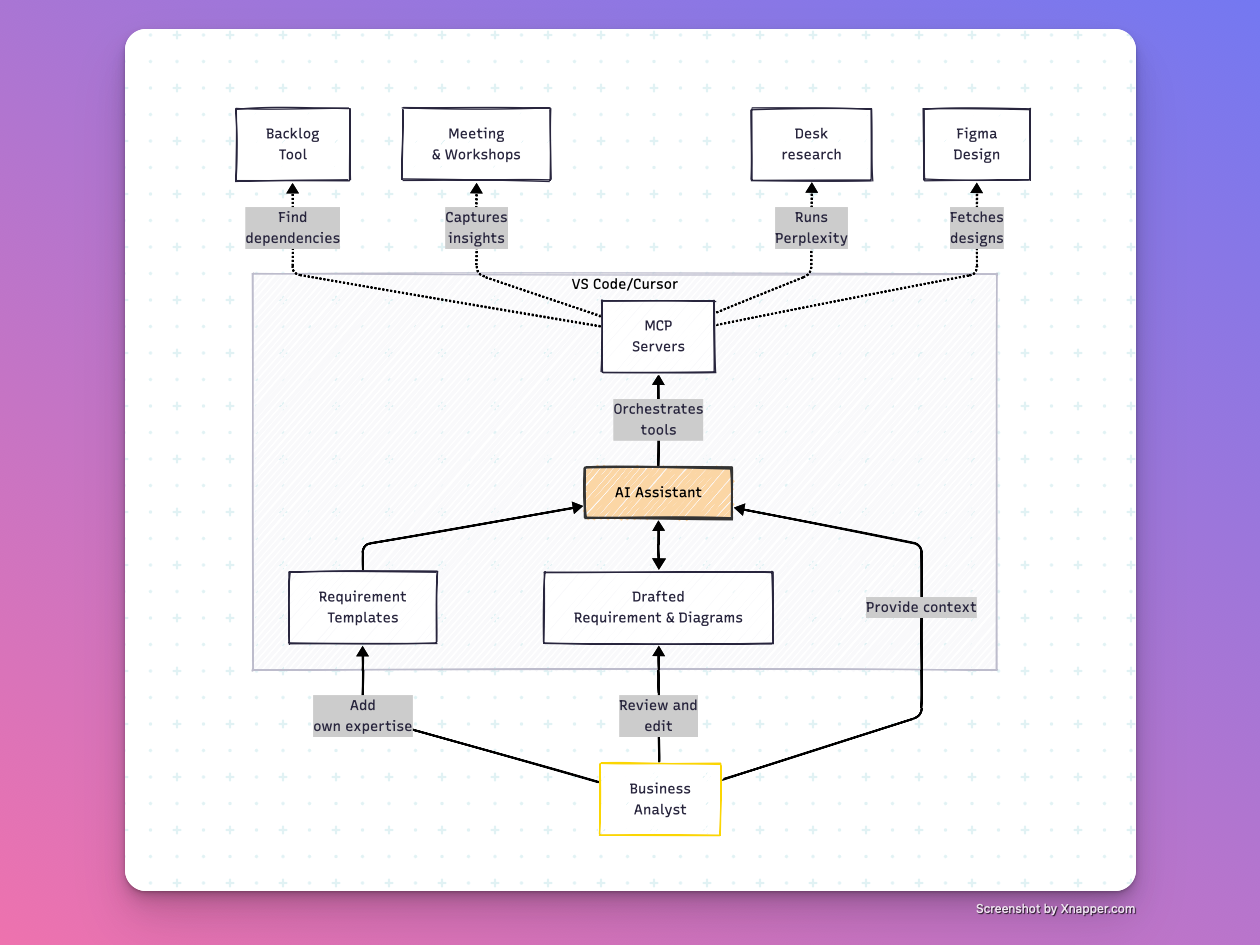
**How you will be working**
3. Tools & Setup
This guide shows you how to set up your workspace so you can manage your backlog with help from AI. You only need to do it once - just follow the steps and you’ll be ready to go.
3.1 Installation and Configuration
Installation (VS Code or Cursor)
VS Code Installation:
- Navigate to code.visualstudio.com
- Download the version for your operating system
- Run the installer with default settings
- Important for macOS users: If prompted about opening an app from an unidentified developer, go to System Preferences > Security & Privacy to allow it
Cursor Installation:
- Navigate to cursor.sh
- Download the installer
- Follow the installation wizard
Recommended settings
For optimal experience with backlog management, add these settings to your settings.json file. These settings are specifically tuned for working with markdown files and managing project documentation:
{
// Editor Setting
"files.autoSave": "afterDelay",
"files.autoSaveDelay": 1000,
"editor.wordWrap": "on",
"editor.fontSize": 12,
"editor.lineHeight": 1.5,
"markdown.preview.breaks": true,
"markdown.preview.linkify": true,
"editor.defaultFoldingRangeProvider": "vscode.markdown-language-features",
"editor.defaultFormatter": "vscode.markdown-language-features",
"workbench.startupEditor": "none",
"files.associations": {
"*.md": "markdown"
},
// Explorer & File Management
"explorer.sortOrder": "type",
"explorer.compactFolders": false,
"workbench.editor.enablePreview": false,
// Document Navigation & Reading
"editor.minimap.enabled": true,
"editor.minimap.showSlider": "always",
"editor.minimap.side": "right",
"breadcrumbs.enabled": true,
"outline.showProperties": true,
// Text Editing Enhancements
"editor.suggest.showWords": true,
"editor.wordBasedSuggestions": "allDocuments",
"editor.quickSuggestions": {
"other": true,
"comments": true,
"strings": true
},
// Layout Optimization
"workbench.sideBar.location": "left",
"workbench.panel.defaultLocation": "bottom",
"workbench.statusBar.visible": true,
"github.copilot.advanced": {
},
"github.copilot.chat.codesearch.enabled": true,
"github.copilot.chat.agent.thinkingTool": true,
"github.copilot.chat.search.keywordSuggestions": true,
}
What these settings do:
- Auto-save: Prevents losing work with automatic saving every second
- Word wrap: Makes long lines readable without horizontal scrolling
- Markdown preview: Enables live preview of your tickets as you write them
- File associations: Ensures all
.mdfiles are treated as markdown - Explorer settings: Organizes files by type and shows full folder structure
- Navigation aids: Minimap and breadcrumbs help navigate large documents
- Quick suggestions: Provides intelligent autocomplete for faster writing
Workspace folder structure
A well-organized folder is critical. Use this structure inside your main project folder:
Backlog/
├── Feature [37732] Workflow Builder/
│ ├── Feature [37732] Workflow Builder.md
│ ├── [Backend] [37733] Deadband for bulk automation trigger.md
│ ├── [Backend] [37734] API endpoint configuration.md
│ ├── [Design] [37735] User interface wireframes.md
│ ├── [Web] [37736] Frontend component development.md
│ └── [Web] [37737] Integration testing suite.md
├── Feature [38001] Mobile Authentication/
│ ├── Feature [38001] Mobile Authentication.md
│ ├── [Mobile] [38002] Biometric login integration.md
│ ├── [Backend] [38003] OAuth2 implementation.md
│ └── [Design] [38004] Login flow redesign.md
└── Technical docs/ #
File naming convention
- Feature Folders:
Feature [ID] Title- Example:
Feature [37732] Workflow Builder
- Example:
- Feature Files:
Feature [ID] Title.md- Example:
Feature [37732] Workflow Builder.md
- Example:
- PBI Files:
[Type] [ID] Title.md- Example:
[Backend] [37733] Deadband for bulk automation trigger.md
- Example:
Importing Backlog Items
Recommendation: Start small! Import only the features you’re actively working on. Don’t try to import your entire backlog at once.
There are three main approaches to get your backlog items from Azure DevOps into your local workspace:
- Option 1: Azure DevOps MCP Serves
This is the most powerful option that enables direct AI conversation with your Azure DevOps backlog. See Part D for MCP setup instructions. Once configured, you can use prompts like this:@azure-devops Get details for Feature 37732 "Workflow Builder" and all its related PBIs. Format them according to our folder structure and create markdown files.
Follow instructions from there to set up this MCP: https://github.com/microsoft/azure-devops-mcp - Option 2: CSV Export with Make.com Automation (without access via API)
- Export from Azure DevOps: Create a query for the items you want, and click “Export to CSV”.
- Process with Make.com: Use a Make.com scenario to convert the CSV rows to properly formatted Markdown files. This can be uploaded to a service like Dropbox for easy download.
- Copy Files: Copy the generated
.mdfiles into your project’sBacklog/folder.
- Option 3: Direct API Integration with Bash Script (with access via API)
For importing individual items, you can use a bash script withjqandpandocto fetch and convert work items directly from the Azure DevOps API.- Prerequisites
Before setting up the script, ensure you have these tools installed:
1. Install Required Tools# On macOS (using Homebrew)brew install jq pandoc curl # On Windows (using Chocolatey)choco install jq pandoc curl - How to get Personal access token Azure DevOps
- Open User settings ▸ Personal access tokens and click ➕ New Token.
- Give the token a clear Name, and set an Expiration (30–90 days is common).
- Click Show all scopes and enable only what you need:
- Work Items → Read – minimum for dependency search, MCP #search_work_item, and the get-workitem.sh script.
- Work Items → Read & write – add only if you’ll create or update PBIs from VS Code.
- Press Create and copy the token now—it won’t be shown again.
Your PAT is now ready for VS Code tasks, MCP servers, and any scripts in this guide.
- Script setup
1: Create the Script File Create a file named get-workitem.sh and get-feature-with-pbis.sh- get-workitem.sh
#!/bin/bash # Check if the work item ID is provided if [ -z "$1" ]; then echo "Usage: # Process each relation while read -r RELATION_URL RELATION_TYPE; do if [ -n "$RELATION_URL" ]; then # Extract work item ID from URL RELATED_ID=$(echo "$RELATION_URL" | awk -F/ '{print $NF}') echo "Found related item ID: $RELATED_ID" # Skip GitHub artifacts and other non-numeric IDs if [[ ! "$RELATED_ID" =~ ^[0-9]+$ ]]; then echo "Skipping non-work item artifact: $RELATED_ID" continue fi # Get the relation work item details RELATED_RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$RELATED_ID?api-version=7.1") # Check if response is valid JSON if ! echo "$RELATED_RESPONSE" | jq . > /dev/null 2>&1; then echo "Warning: Invalid JSON response for related item $RELATED_ID" continue }d>" exit 1 fi ## Configuration PAT="your-pat" ORG="your-org" PROJECT="your-project" WORK_ITEM_ID="$1" # API endpoint - add $expand=relations to get parent information URL="https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$WORK_ITEM_ID?api-version=7.1&\$expand=relations" # Retrieve work item RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "$URL") # Check if the response is valid JSON before proceeding if ! echo "$RESPONSE" | jq . > /dev/null 2>&1; then echo "Error: Invalid JSON response received from API." echo "Response: $RESPONSE" exit 1 fi # Check if the API returned an error if echo "$RESPONSE" | jq -e '.error' > /dev/null 2>&1; then ERROR_MSG=$(echo "$RESPONSE" | jq -r '.error.message') echo "API Error: $ERROR_MSG" exit 1 fi # Extract fields using jq with fallbacks and error handling TITLE=$(echo "$RESPONSE" | jq -r '.fields["System.Title"] // "No Title"' 2>/dev/null || echo "No Title") WORK_ITEM_TYPE=$(echo "$RESPONSE" | jq -r '.fields["System.WorkItemType"] // "Unknown Type"' 2>/dev/null || echo "Unknown Type") STATE=$(echo "$RESPONSE" | jq -r '.fields["System.State"] // "Unknown State"' 2>/dev/null || echo "Unknown State") DESCRIPTION_HTML=$(echo "$RESPONSE" | jq -r '.fields["System.Description"] // ""' 2>/dev/null || echo "") ACCEPTANCE_CRITERIA_HTML=$(echo "$RESPONSE" | jq -r '.fields["Microsoft.VSTS.Common.AcceptanceCriteria"] // ""' 2>/dev/null || echo "") ITEM_URL=$(echo "$RESPONSE" | jq -r '._links.html.href // ""' 2>/dev/null || echo "") # Extract assignee information if it exists if echo "$RESPONSE" | jq -e '.fields["System.AssignedTo"]' > /dev/null; then ASSIGNED_TO=$(echo "$RESPONSE" | jq -r '.fields["System.AssignedTo"].displayName') else ASSIGNED_TO="Unassigned" fi # Extract Parent ID if exists PARENT_ID=$(echo "$RESPONSE" | jq -r '.relations[]? | select(.rel=="System.LinkTypes.Hierarchy-Reverse") | .url' | awk -F/ '{print $NF}' 2>/dev/null || echo "") if [ -n "$PARENT_ID" ]; then # Retrieve parent work item to get its type PARENT_RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$PARENT_ID?api-version=7.1") if ! echo "$PARENT_RESPONSE" | jq . > /dev/null 2>&1; then PARENT_TYPE="Unknown" PARENT_TITLE="Unknown" else PARENT_TYPE=$(echo "$PARENT_RESPONSE" | jq -r '.fields["System.WorkItemType"]' 2>/dev/null || echo "Unknown") PARENT_TITLE=$(echo "$PARENT_RESPONSE" | jq -r '.fields["System.Title"]' 2>/dev/null || echo "Unknown") fi PARENT_INFO="$PARENT_TYPE $PARENT_ID: $PARENT_TITLE" else PARENT_INFO="None" fi # Extract related work items (excluding parent/child relations) RELATED_ITEMS="" if echo "$RESPONSE" | jq -e '.relations[]? | select(.rel != "System.LinkTypes.Hierarchy-Reverse" and .rel != "System.LinkTypes.Hierarchy-Forward")' > /dev/null 2>&1; then # Process each relation while read -r RELATION_URL RELATION_TYPE; do if [ -n "$RELATION_URL" ]; then # Extract work item ID from URL RELATED_ID=$(echo "$RELATION_URL" | awk -F/ '{print $NF}') # Skip GitHub artifacts and other non-numeric IDs if [[ ! "$RELATED_ID" =~ ^[0-9]+$ ]]; then continue fi # Format the relation type for display FORMATTED_REL_TYPE=$(echo "$RELATION_TYPE" | sed 's/System.LinkTypes.//g' | sed 's/-/ /g') # Append to our list of related items with just the ID if [ -z "$RELATED_ITEMS" ]; then RELATED_ITEMS="- $FORMATTED_REL_TYPE: Item $RELATED_ID" else RELATED_ITEMS="$RELATED_ITEMS - $FORMATTED_REL_TYPE: Item $RELATED_ID" fi fi done < <(echo "$RESPONSE" | jq -r '.relations[]? | select(.rel != "System.LinkTypes.Hierarchy-Reverse" and .rel != "System.LinkTypes.Hierarchy-Forward") | [.url, .rel] | @tsv' 2>/dev/null || echo) fi # If no related items were found, set to None if [ -z "$RELATED_ITEMS" ]; then RELATED_ITEMS="None" fi # Function to convert HTML to plain text using pandoc convert_html_to_text() { local html_content="$1" if [ -n "$html_content" ]; then # Convert HTML to Markdown with pandoc # Then, use sed to remove various HTML tags # Finally, remove any resulting empty lines echo "$html_content" | pandoc -f html -t markdown_strict --wrap=none | \ sed -E 's,</?span[^>]*>,,gi; s,</?strike>,,gi; s,</?b>,,gi; s,</?strong>,,gi; s,</?s>,,gi; s,</?div[^>]*>,,gi; s,</?p[^>]*>,,gi; s,</?ul[^>]*>,,gi; s,</?ol[^>]*>,,gi; s,</?li[^>]*>,,gi; s,<br/?>,,gi' | \ sed '/^$/d' else echo "None" fi } # Convert HTML fields to plain text - enhance to remove more HTML tags DESCRIPTION_TEXT=$(convert_html_to_text "$DESCRIPTION_HTML") ACCEPTANCE_CRITERIA_TEXT=$(convert_html_to_text "$ACCEPTANCE_CRITERIA_HTML") # Create Markdown content MARKDOWN_CONTENT=$(cat <<EOF Metadata: Work Item Type: $WORK_ITEM_TYPE Title: $TITLE Parent Item: $PARENT_INFO Item ID: $WORK_ITEM_ID State: $STATE URL: $ITEM_URL EOF ) # Add related PBIs to the metadata if they exist if [ "$RELATED_ITEMS" != "None" ]; then MARKDOWN_CONTENT="$MARKDOWN_CONTENT Related PBIs: $RELATED_ITEMS" fi # Complete the markdown content MARKDOWN_CONTENT="$MARKDOWN_CONTENT ____ Description: $DESCRIPTION_TEXT ____ Acceptance Criteria: $ACCEPTANCE_CRITERIA_TEXT" # Sanitize the title for use in a filename, allowing spaces and brackets, removing other problematic characters SANITIZED_TITLE=$(echo "$TITLE" | sed 's/[^a-zA-Z0-9_.\\-\\[\\] ]//g') # If SANITIZED_TITLE is empty after sanitization (e.g. title was all special chars), use work item ID if [ -z "$SANITIZED_TITLE" ]; then SANITIZED_TITLE="work-item-$WORK_ITEM_ID" fi # Check if this is a child work item with a parent ID # Get the absolute path to the workspace root directory WORKSPACE_ROOT="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)" BACKLOG_DIR="$WORKSPACE_ROOT/Backlog" # Ensure Backlog directory exists at the workspace root if [ ! -d "$BACKLOG_DIR" ]; then mkdir -p "$BACKLOG_DIR" fi # Default save location is Backlog directory SAVE_DIRECTORY="$BACKLOG_DIR" if [ "$PARENT_INFO" != "None" ]; then # Extract parent type and ID from the PARENT_INFO (which is in format "Type ID: Title") PARENT_TYPE=$(echo "$PARENT_INFO" | awk '{print $1}') PARENT_ID_ONLY=$(echo "$PARENT_INFO" | awk '{print $2}' | sed 's/:$//') # Skip parent folder creation for Features with Epic parents if [ "$WORK_ITEM_TYPE" = "Feature" ] && [ "$PARENT_TYPE" = "Epic" ]; then # For Features with Epic parents, save directly to Backlog directory, not in parent Epic folder echo "Feature detected with Epic parent. Saving directly to Backlog directory." else # For all other cases (PBIs with Feature parents, etc.), use parent folder # Get parent title for the folder name PARENT_RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$PARENT_ID_ONLY?api-version=7.1") PARENT_TITLE=$(echo "$PARENT_RESPONSE" | jq -r '.fields["System.Title"] // "No Title"' 2>/dev/null || echo "No Title") PARENT_SANITIZED_TITLE=$(echo "$PARENT_TITLE" | sed 's/[^a-zA-Z0-9_.\\-\\[\\] ]//g') # Create new folder name format: [ID] Title if [ -z "$PARENT_SANITIZED_TITLE" ]; then PARENT_SANITIZED_TITLE="Feature $PARENT_ID_ONLY" fi NEW_FOLDER_NAME="[$PARENT_ID_ONLY] $PARENT_SANITIZED_TITLE" # Check both folder formats - new and old NEW_FEATURE_FOLDER="$BACKLOG_DIR/$NEW_FOLDER_NAME" OLD_FEATURE_FOLDER="$BACKLOG_DIR/Feature $PARENT_ID_ONLY" if [ -d "$NEW_FEATURE_FOLDER" ]; then # Use new format if it exists FEATURE_FOLDER="$NEW_FEATURE_FOLDER" elif [ -d "$OLD_FEATURE_FOLDER" ]; then # If only old format exists, use it (don't rename here) FEATURE_FOLDER="$OLD_FEATURE_FOLDER" else # Create new format if neither exists FEATURE_FOLDER="$NEW_FEATURE_FOLDER" mkdir -p "$FEATURE_FOLDER" fi SAVE_DIRECTORY="$FEATURE_FOLDER" fi fi # Save to .md file in the appropriate directory # Format is [Type][ID] Title for all work items, with underscore prefix for Features to make them sort first if [ "$WORK_ITEM_TYPE" = "Feature" ]; then # For Feature type, use _[Feature][ID] Title format to make it sort first FILENAME="$SAVE_DIRECTORY/_[${WORK_ITEM_TYPE}][${WORK_ITEM_ID}] ${SANITIZED_TITLE}.md" elif [[ "$SANITIZED_TITLE" =~ ^\[[A-Za-z]+\].* ]]; then # If the title already has a prefix like [WEB], use [Type][ID] existing-title.md PREFIX=$(echo "$SANITIZED_TITLE" | grep -o '^\[[A-Za-z]\+\]') REST_OF_TITLE=$(echo "$SANITIZED_TITLE" | sed -E 's/^\[[A-Za-z]+\]//') FILENAME="$SAVE_DIRECTORY/${PREFIX}[${WORK_ITEM_ID}]${REST_OF_TITLE}.md" else # For other types, use [Type][ID] Title format FILENAME="$SAVE_DIRECTORY/[${WORK_ITEM_TYPE}][${WORK_ITEM_ID}] ${SANITIZED_TITLE}.md" fi echo "$MARKDOWN_CONTENT" > "$FILENAME" echo "Work item saved to $FILENAME" - get-feature-with-all-pbis
#!/bin/bash # Check if the feature ID is provided if [ -z "$1" ]; then echo "Usage: $0 <feature_id>" echo "Example: $0 60669" exit 1 fi # Configuration PAT="your-pat" ORG="your-org" PROJECT="your-project" FEATURE_ID="$1" # Get the path to the script's directory SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)" # Get the absolute path to the workspace root directory WORKSPACE_ROOT="$(cd "$SCRIPT_DIR/.." && pwd)" BACKLOG_DIR="$WORKSPACE_ROOT/Backlog" # Get the feature title for the folder name FEATURE_RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$FEATURE_ID?api-version=7.1") FEATURE_TITLE=$(echo "$FEATURE_RESPONSE" | jq -r '.fields["System.Title"] // "No Title"' 2>/dev/null || echo "No Title") FEATURE_SANITIZED_TITLE=$(echo "$FEATURE_TITLE" | sed 's/[^a-zA-Z0-9_.\\-\\[\\] ]//g') # If title was sanitized to empty, use work item ID if [ -z "$FEATURE_SANITIZED_TITLE" ]; then FEATURE_SANITIZED_TITLE="Feature $FEATURE_ID" fi # Create new folder name format: [ID] Title NEW_FOLDER_NAME="[$FEATURE_ID] $FEATURE_SANITIZED_TITLE" FEATURE_FOLDER="$BACKLOG_DIR/$NEW_FOLDER_NAME" OLD_FEATURE_FOLDER="$BACKLOG_DIR/Feature $FEATURE_ID" # Ensure Backlog directory exists if [ ! -d "$BACKLOG_DIR" ]; then mkdir -p "$BACKLOG_DIR" fi # Check if the old or new feature folder exists if [ -d "$OLD_FEATURE_FOLDER" ] && [ "$OLD_FEATURE_FOLDER" != "$FEATURE_FOLDER" ]; then echo "Found old-format feature folder: Feature $FEATURE_ID" echo "Renaming folder to: $NEW_FOLDER_NAME" mv "$OLD_FEATURE_FOLDER" "$FEATURE_FOLDER" elif [ ! -d "$FEATURE_FOLDER" ]; then echo "Creating feature folder: $NEW_FOLDER_NAME" mkdir -p "$FEATURE_FOLDER" else echo "Feature folder already exists: $NEW_FOLDER_NAME" fi # Create the new preferred filename format: _[Type][ID] Title to ensure it appears at the top PREFERRED_FEATURE_FILENAME="_[Feature][${FEATURE_ID}] $FEATURE_SANITIZED_TITLE.md" # First, fetch the feature itself echo "Fetching feature with ID: $FEATURE_ID" "$SCRIPT_DIR/get-workitem.sh" "$FEATURE_ID" # Check other Backlog directories for the feature file echo "Looking for feature file to move to its folder..." # First look for any feature file matching by title find "$BACKLOG_DIR" -type f -name "${FEATURE_SANITIZED_TITLE}.md" | while read -r found_file; do # Skip if the file is already in the correct folder if [[ "$found_file" != "$FEATURE_FOLDER/"* ]]; then echo "Found feature file at $found_file" echo "Moving and renaming to $FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" mv "$found_file" "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" fi done # Also look for any feature file with the correct ID but in wrong folder find "$BACKLOG_DIR" -type f -name "*Feature*$FEATURE_ID*" | while read -r found_file; do # Skip if the file is already in the correct folder if [[ "$found_file" != "$FEATURE_FOLDER/"* ]]; then echo "Found feature file by ID at $found_file" echo "Moving and renaming to $FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" mv "$found_file" "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" fi done # Also look for any files in old-format Feature folder if it still exists if [ -d "$BACKLOG_DIR/Feature $FEATURE_ID" ] && [ "$BACKLOG_DIR/Feature $FEATURE_ID" != "$FEATURE_FOLDER" ]; then echo "Looking for files in old feature folder format..." find "$BACKLOG_DIR/Feature $FEATURE_ID" -type f -name "*.md" | while read -r found_file; do filename=$(basename "$found_file") echo "Moving $filename from old feature folder to new feature folder" mv "$found_file" "$FEATURE_FOLDER/" done # Try to remove the old folder if it's empty rmdir "$BACKLOG_DIR/Feature $FEATURE_ID" 2>/dev/null || true fi # Also check if the file is already in the feature folder but needs renaming FEATURE_FILE_IN_FOLDER="$FEATURE_FOLDER/${FEATURE_SANITIZED_TITLE}.md" if [ -f "$FEATURE_FILE_IN_FOLDER" ] && [ "$FEATURE_FILE_IN_FOLDER" != "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" ]; then echo "Renaming feature file to follow the _[Feature][ID] Title format" mv "$FEATURE_FILE_IN_FOLDER" "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" fi # Also check for feature files that have the old [Feature][ID] naming format but no underscore OLD_FEATURE_FILENAME="$FEATURE_FOLDER/[Feature][${FEATURE_ID}] $FEATURE_SANITIZED_TITLE.md" if [ -f "$OLD_FEATURE_FILENAME" ] && [ "$OLD_FEATURE_FILENAME" != "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" ]; then echo "Renaming feature file to add underscore prefix" mv "$OLD_FEATURE_FILENAME" "$FEATURE_FOLDER/$PREFERRED_FEATURE_FILENAME" fi # API endpoint to get the feature with relations URL="https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$FEATURE_ID?api-version=7.1&\$expand=relations" # Retrieve feature work item with relations echo "Retrieving child PBIs for feature $FEATURE_ID..." RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "$URL") # Check if the response is valid JSON before proceeding if ! echo "$RESPONSE" | jq . > /dev/null 2>&1; then echo "Error: Invalid JSON response received from API." echo "Response: $RESPONSE" exit 1 fi # Check if the API returned an error if echo "$RESPONSE" | jq -e '.error' > /dev/null 2>&1; then ERROR_MSG=$(echo "$RESPONSE" | jq -r '.error.message') echo "API Error: $ERROR_MSG" exit 1 fi # Extract child work item IDs (items with Hierarchy-Forward relationship) CHILD_IDS=$(echo "$RESPONSE" | jq -r '.relations[]? | select(.rel=="System.LinkTypes.Hierarchy-Forward") | .url | split("/")[-1]') if [ -z "$CHILD_IDS" ]; then echo "No child PBIs found for feature $FEATURE_ID." exit 0 fi # Count the number of child PBIs PBI_COUNT=$(echo "$CHILD_IDS" | wc -l | tr -d '[:space:]') echo "Found $PBI_COUNT child PBIs for feature $FEATURE_ID." # Fetch each child PBI echo "Fetching child PBIs..." while read -r CHILD_ID; do if [ -n "$CHILD_ID" ]; then echo "Fetching PBI with ID: $CHILD_ID" "$SCRIPT_DIR/get-workitem.sh" "$CHILD_ID" # Move the PBI file to the feature folder if it was saved elsewhere # Get the PBI title to identify its file PBI_RESPONSE=$(curl -s -u :$PAT -H "Content-Type: application/json" "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/$CHILD_ID?api-version=7.1") PBI_TITLE=$(echo "$PBI_RESPONSE" | jq -r '.fields["System.Title"] // "No Title"' 2>/dev/null || echo "No Title") PBI_TYPE=$(echo "$PBI_RESPONSE" | jq -r '.fields["System.WorkItemType"] // "PBI"' 2>/dev/null || echo "PBI") SANITIZED_TITLE=$(echo "$PBI_TITLE" | sed 's/[^a-zA-Z0-9_.\\-\\[\\] ]//g') # If title was sanitized to empty, use work item ID if [ -z "$SANITIZED_TITLE" ]; then SANITIZED_TITLE="work-item-$CHILD_ID" fi # Format the PBI filename as [Type][ID] Title if [[ "$SANITIZED_TITLE" =~ ^\[[A-Za-z]+\].* ]]; then # If the title already has a prefix like [WEB], use [Type][ID] format PREFIX=$(echo "$SANITIZED_TITLE" | grep -o '^\[[A-Za-z]\+\]') REST_OF_TITLE=$(echo "$SANITIZED_TITLE" | sed -E 's/^\[[A-Za-z]+\]//') PREFERRED_PBI_FILENAME="${PREFIX}[${CHILD_ID}]${REST_OF_TITLE}.md" else # For other PBIs, use [Type][ID] Title format PREFERRED_PBI_FILENAME="[${PBI_TYPE}][${CHILD_ID}] ${SANITIZED_TITLE}.md" fi # Check if the file is in the Backlog directory instead of feature folder PBI_FILE="$BACKLOG_DIR/${SANITIZED_TITLE}.md" if [ -f "$PBI_FILE" ]; then echo "Moving $PBI_FILE to feature folder as $PREFERRED_PBI_FILENAME" mv "$PBI_FILE" "$FEATURE_FOLDER/$PREFERRED_PBI_FILENAME" fi # Also check if the PBI is in an old format feature folder OLD_PBI_FILE="$BACKLOG_DIR/Feature $FEATURE_ID/${SANITIZED_TITLE}.md" if [ -f "$OLD_PBI_FILE" ] && [ "$BACKLOG_DIR/Feature $FEATURE_ID" != "$FEATURE_FOLDER" ]; then echo "Found PBI in old feature folder format, moving to new folder as $PREFERRED_PBI_FILENAME" mv "$OLD_PBI_FILE" "$FEATURE_FOLDER/$PREFERRED_PBI_FILENAME" fi fi done <<< "$CHILD_IDS" echo "Finished fetching feature and all child PBIs." echo "All items are now organized in: $FEATURE_FOLDER"
2: Configure your access Edit the both scripts and update these three lines with your actual values:# Configuration PAT="your personal access token" ORG="your organzation" PROJECT="you project"
Note: You can find the ORG and PROJECT values directly in the URL when you open your Azure DevOps backlog. For example, in https://dev.azure.com/your-org-name/your-project-name/_workitems, your-org-name is your ORG, and your-project-name is your PROJECT.
3: Make the scripts executablechmod +x get-workitem.sh chmod +x get-feature-with-all-pbis.sh - get-workitem.sh
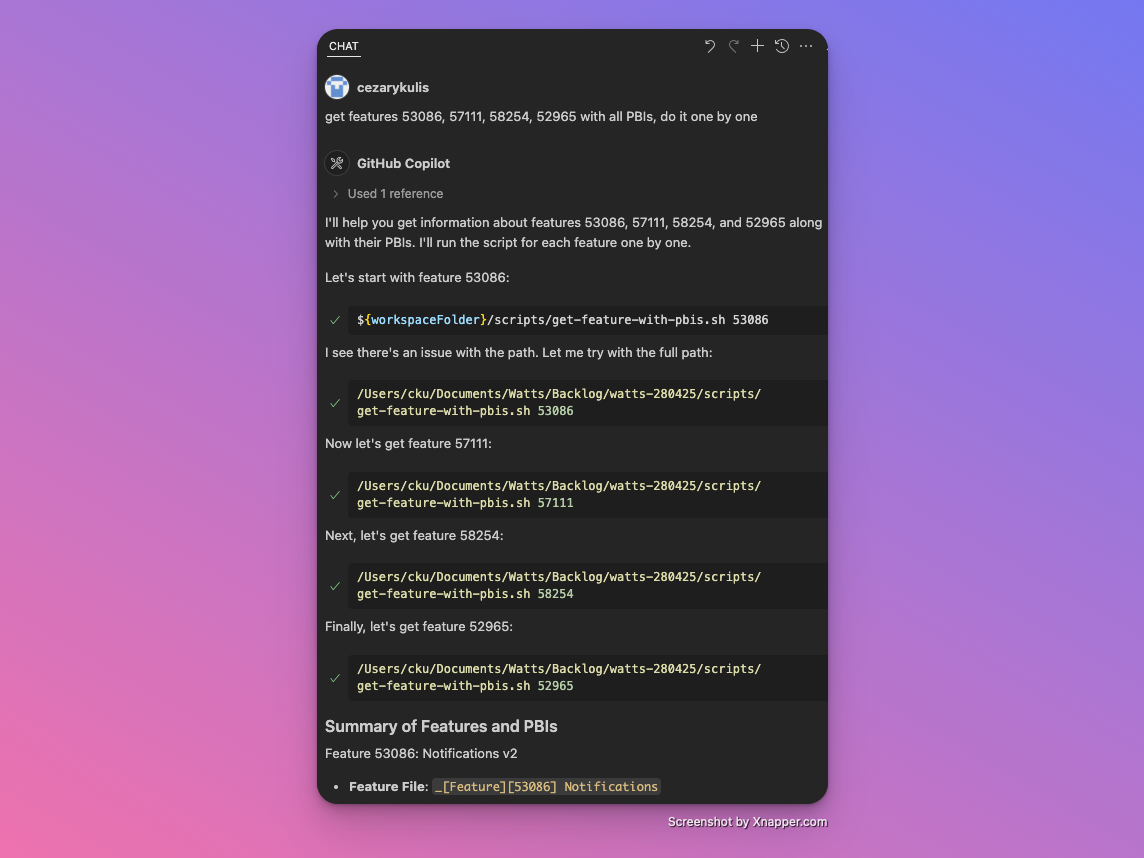
- Usage Examples
Import a single work item:./get-workitem.sh 37732
Import feature with PBIs :./get-feature-with-all-pbis.sh 37732
What the Script Does- Fetches work item data from Azure DevOps API
- Extracts all relevant fields (title, description, acceptance criteria, etc.)
- Handles parent-child relationships and creates proper folder structure
- Converts HTML to Markdown using pandoc
- Organizes files automatically into Feature folders
- Sanitizes filenames for compatibility
- Includes metadata for easy reference
- Troubleshooting
- “Permission denied”: Run
chmod +x import-work-item.sh - “pandoc: command not found”: Install pandoc using your package manager
- “Invalid JSON response”: Check your PAT, org name, and project name
- “API Error”: Verify your PAT has the correct permissions
- “Permission denied”: Run
- Prerequisites
Publish Items to Backlog
Once your tickets are reviewed and finalized locally, you can publish them directly to your backlog (for example, Azure DevOps) using the API.
1. Create the publish script
Start by creating a shell script that will send the ticket to your backlog using Azure DevOps API. You’ll insert your personal access token and workspace details into the script as for using scripts to import items from backlog.
- Example script file: create_pbi.sh
#!/usr/bin/env bash # Enable debugging to see all commands executed # helper to pull values like "Title: …" kv() { echo "$META" | grep -E "^$1:[[:blank:]]*" | sed -E "s/^$1:[[:blank:]]*//"; } ################################################################################ # create_pbi.sh – create a new Product Backlog Item in Azure DevOps Boards # # LAYOUT EXPECTED IN THE MARKDOWN FILE # ## Metadata: # Work Item Type: Product Backlog Item # Title: My PBI title # Parent Item: 12345 # ← optional # ____ # # Description: # (multi-line markdown …) # ____ # # Acceptance Criteria: # (multi-line markdown …) # # USAGE: # ./create_pbi.sh path/to/item.md ################################################################################ # 👉 EDIT THESE THREE VALUES PAT="your token" ORG="your organization" PROJECT="your project" # READ AND VALIDATE ARGUMENT ############################################################################### if [[ $# -ne 1 ]]; then # If no argument provided, check if this is being run from VS Code task with active file if [[ -n "$VSCODE_PID" && -n "$FILE" ]]; then echo "Using currently opened file: $FILE" else echo "USAGE: $0 <markdown-file>" >&2 exit 1 fi else FILE="$1" fi # Verify the file exists [[ ! -f "$FILE" ]] && { echo "File not found: $FILE" >&2; exit 1; } # PARSE METADATA, DESCRIPTION, ACCEPTANCE CRITERIA (BSD-awk friendly) ############################################################################### # ---- grab Metadata block ----------------------------------------------------- META=$(awk ' /^##[[:blank:]]+Metadata:/ {meta=1; next} # start capturing /^____/ && meta {exit} # stop at the horizontal rule meta {print} ' "$FILE") # helper to pull values like “Title: …” kv() { echo "$META" | grep -E "^$1:[[:blank:]]*" | sed -E "s/^$1:[[:blank:]]*//"; } TITLE="$(kv 'Title')" [[ -z "$TITLE" ]] && TITLE="$(basename "$FILE" .md)" TITLE_ESC=${TITLE//\"/\\\"} PARENT_ID="$(kv 'Parent Item' | tr -dc '0-9')" # ---- Description block ------------------------------------------------------- # Process the description with proper HTML formatting for ADO DESCRIPTION=$(awk ' BEGIN { in_section = 0; buffer = "" } /^Description:/ { in_section = 1; next } /^____/ && in_section { in_section = 0; next } /^Acceptance Criteria:/ { in_section = 0; next } in_section && /^$/ { buffer = buffer "<br/><br/>"; next } # Empty lines become double breaks in_section && /^\*/ { buffer = buffer "<br/>" $0; next } # List items get a break before in_section { buffer = buffer $0 " " } # Normal lines get space at end END { print buffer } ' "$FILE" | sed 's/"/\\"/g') # ---- Acceptance Criteria ----------------------------------------------------- # Process the acceptance criteria with proper HTML formatting for Gherkin syntax in ADO ACCEPTANCE_CRITERIA=$(awk ' BEGIN { in_section = 0; buffer = "" } /^Acceptance Criteria:/ { in_section = 1; next } /^____/ && in_section { in_section = 0; next } in_section && /^Scenario:/ { buffer = buffer "<br/><b>" $0 "</b><br/>"; next } # Bold scenario titles in_section && /^Given/ { buffer = buffer "<b>Given</b> " substr($0, 6) "<br/>"; next } # Gherkin Given bold in_section && /^When/ { buffer = buffer "<b>When</b> " substr($0, 5) "<br/>"; next } # Gherkin When bold in_section && /^Then/ { buffer = buffer "<b>Then</b> " substr($0, 5) "<br/>"; next } # Gherkin Then bold in_section && /^And/ { buffer = buffer "<b>And</b> " substr($0, 4) "<br/>"; next } # Gherkin And bold END { print buffer } ' "$FILE" | sed 's/"/\\"/g') # BUILD JSON-PATCH PAYLOAD ############################################################################### read -r -d '' PAYLOAD <<EOF [ { "op": "add", "path": "/fields/System.Title", "value": "$TITLE_ESC" }, { "op": "add", "path": "/fields/System.State", "value": "New" }, { "op": "add", "path": "/fields/System.Description", "value": "$DESCRIPTION" }, { "op": "add", "path": "/fields/Microsoft.VSTS.Common.AcceptanceCriteria", "value": "$ACCEPTANCE_CRITERIA" }$( [[ -n "$PARENT_ID" ]] && cat <<EOR , { "op": "add", "path": "/relations/-", "value": { "rel": "System.LinkTypes.Hierarchy-Reverse", "url": "https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workItems/$PARENT_ID" } } EOR ) ] EOF # POST TO AZURE DEVOPS ############################################################################### URL="https://dev.azure.com/$ORG/$PROJECT/_apis/wit/workitems/\$Product%20Backlog%20Item?api-version=7.1" # Send the request to Azure DevOps and get the response (just the data, not verbose headers) RESPONSE=$(curl -s -X POST \ -H "Content-Type: application/json-patch+json" \ -u ":$PAT" \ -d "$PAYLOAD" \ "$URL") # Extract the work item ID and link NEW_ID=$(echo "$RESPONSE" | jq -r '.id') LINK=$(echo "$RESPONSE" | jq -r '._links.html.href') if [[ "$NEW_ID" == "null" ]]; then echo "❌ Failed to create PBI" >&2 echo "$RESPONSE" | jq . >&2 exit 1 fi echo "✅ Created PBI #$NEW_ID" echo "🔗 $LINK"
Update the configuration section with your own values:
# Configuration
PAT="your personal access token"
ORG="your organization"
PROJECT="your project"
Note: You can find the ORG and PROJECT values directly in the URL when you open your Azure DevOps backlog.
For example: https://dev.azure.com/your-org-name/your-project-name/_workitems Here, your-org-name is your ORG, and your-project-name is your PROJECT.
2. Make the script executable
Run the following command in your terminal:
chmod +x create_pbi.sh
4. Add a VS Code task for quick access
To run the publish command quicker, add a task to .vscode/tasks.json:
{
"version": "2.0.0",
"tasks": [
{
"label": "Push current backlog file to ADO",
"type": "shell",
"command": "${workspaceFolder}/scripts/create-workitem.sh",
"args": [
"${file}" // ← the file you are editing
],
"presentation": {
"echo": true, // show the exact command
"reveal": "always", // keep terminal visible
"panel": "shared"
},
"problemMatcher": []
},
]
}
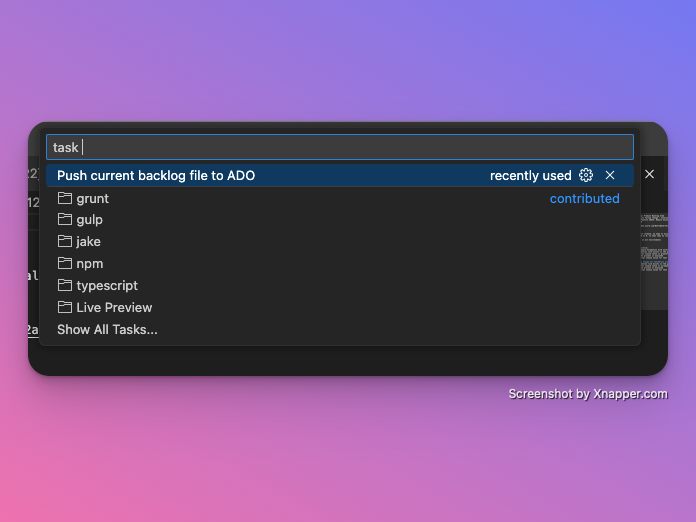
This allows you to trigger publishing from the command palette.
Note: You might need to adjust the script depending on how your backlog is set up — such as custom work item types, required fields, or field mappings.
3.2 Extensions
GitHub Copilot Setup
1: Account & Subscription
- You will need a GitHub Copilot subscription.
2: Install Extensions
In the Extensions view:
- GitHub Copilot: The core extension.
- GitHub Copilot Chat: Enables the conversational interface.
3: Test Your Assistant
- Basic: In a new
.mdfile, type “As a user, I want to” and see if Copilot offers to complete the sentence (gray text). PressTabto accept. - Chat: Open Copilot Chat and ask it to “Write a user story for a login feature.”
Other Extensions
- 1. Markdown All in One
Adds key features like a table of contents, math support, and auto-preview. - 2. Mermaid Chart Extension Renders diagrams written in Mermaid syntax directly in your markdown files
- Extension Recommendations
To ensure you have the same extensions for consistent workflow, create a.vscode/extensions.jsonfile in your project root:{ "recommendations": [ "github.copilot", "github.copilot-chat", "yzhang.markdown-all-in-one", "mermaidchart.vscode-mermaid-chart", "ms-vscode.vscode-json" ] }
To install all recommended extensions:- Open Command Palette
- Type “Extensions: Show Recommended Extensions”
- Click “Install All” to install all recommended extensions at once
3.3 Prompts
Prompts work differently depending on your editor choice (VS Code vs Cursor), but both serve the same purpose of providing context and instructions to your AI assistant:
Difference between Global and Referenced
1. Global Rules/Instructions (Applied to Every Chat)
- Scope: Automatically applied to every new chat conversation (keep them short to not loose tokens from context window)
- Purpose: Set consistent behavior, project context, and default instructions
- Best for: Project structure, naming conventions, general assistant behavior
2. Referenced Prompts (Used on Demand)
- Scope: Called explicitly when needed
- Purpose: Specific tasks and specialized workflows
- Best for: Targeted operations like formatting tickets, analyzing designs, or searching backlogs
How to use prompts
VS Code (GitHub Copilot):
- Global Instructions:
.github/copilot-instructions.md - Referenced Prompts:
.github/prompts/[prompt-name].md - Usage: Prompts are applied automatically or referenced in chat with
#prompt-name
Cursor:
- Global Rules:
.cursorrulesfile in project root - Master Prompt: Settings > Cursor Tab > Custom Instructions (applies to all chats)
- Referenced Prompts:
.cursorrules/[prompt-name].mpcfiles - Usage: Rules and master prompt apply to every chat; prompts called with
@prompt-name
1. Create Global Rules
For VS Code: Create .github/copilot-instructions.md:
---
applyTo: "**"
---
## Default Instruction for Copilot Chat
You are an **Product-Owner assistant**.
Always answer in English-UK, in Markdown
Feature folders are used to group related PBIs.
Each PBI should be in its own file, named with the format: `[Type]Title.md`.
Each PBI has a unique ID, which is used to reference it in the backlog, in metadata.
Feature folders should be named with the format: `Feature [Feature ID]`.
Technical docs contains technical information that might be useful when working with PBIs.
2. Create referenced prompts
Referenced prompts are specialized instructions that you call on-demand for specific tasks. These are the core prompts that will transform your backlog management workflow:
For VS Code: Create these files in .github/prompts/:
For Cursor: Create these files in .cursorrules/:
- pbi-format.md - Product Backlog Item Template
Purpose: Generate consistently formatted PBI tickets that match your team’s standards. How it works: Provide a brief description and the AI will expand it into a full PBI with description and acceptance criteria.<role> You are a Product Owner's assistant for the IoT Platform, responsible for creating Product Backlog Items (PBIs). </role> <rules> Don't write technical PBIs, instead focus more on bussines logic unless user will ask to create technical one. When creating files for PBIs, always place them in the proper folder structure under Feature number that is a Pranet ID, if not known - ask user to provide Feature numer to become Parent ID. Name always should be as Title. </rules> <context> PLatform is an intelligent, cloud-based water management platform designed for commercial and institutional buildings. It provides real-time monitoring, advanced analytics, and remote control for water systems, aiming to optimize performance, enhance safety, and reduce operational costs. The platform integrates many device types that communicate using MQTT and HTTP protocols. We serve multiple vertical solutions, including: Leak detection systems, Flow meters and environmental sensors Pump controllers and industrial equipment </context> <output format> Use simple english, don't overcomplicate things. Don't use 'the' in Gherkin - Acceptance Criteria. Don't use bulletpoints Don't use Uppercase in Title, unless it's a first letter Keep natural writing style Use always term 'system', not 'backend' ALWAYS FOLLOW markdown syntax when formatiing text list edge cases only if you see strong evidence they will appear always think about different states of components for web application always think about different states of data flows in Iot systems for backend Each section should be separated by ____ (four underscores). </output format> <output example>Metadata:
Work Item Type: Product Backlog Item Title: PlatformClear, descriptive name Platform should be one of: WEB, Backend, Mobile Parent Item: ID of parent feature
Description: When situation/context, I want to motivation/action, so that expected outcome/benefit.
Additional details about implementation requirements and technical context.
Acceptance Criteria: Scenario: descriptive name Given precondition When action Then expected result
Add more scenarios as needed
Edge Cases: List edge cases and relations to other PBIs should be handledEXAMPLES Example 1:
Metadata: Work Item Type: Product Backlog Item Title: Backend Remove triggers, actions, and automation during device deregistration Parent Item: 53086 Item ID: 57590
Description: When a device is deregistered from an organization, I want to automatically clean up all associated automation components, so that the system remains consistent and users don't encounter errors with non-existent devices.
this requires removing the device from all automation triggers and actions, disabling affected automations, and resolving any active alerts related to the device. update device deregistration process to check for automation associations implement cascade deletion for triggers and actions when device is removed add alert resolution logic for affected automations add validation for automations without triggers or actions
Acceptance Criteria: Scenario: Remove Device from Automation Triggers Given an automation exists in the system When a device is deregistered from an organization Then device should be removed from all automation triggers it was associated with And automation should be disabled And alerts should be resolved
Scenario: Remove Device from Automation Actions Given an automation exists in the system When a device is deregistered from an organization Then device should be removed from all automation actions it was associated with And automation should be disabled And alerts should be resolved
Scenario: Delete Automations without Triggers Given an automation exists in the system When all its triggers are removed due to device deregistration Then automation should be deleted
Scenario: No actions assigned validation Given an automation exists with actions When all its actions are removed due to device deregistration Then automation should be disabled And action should be changed to in-app notification to all admin usersExample 2:
Metadata: Work Item Type: Product Backlog Item Title: WEB Copy list of automations associated with deregistered device Parent Item: 53086 Item ID: 57591
Description: When I'm deregistering a device that has associated automations, I want to easily copy the list of affected automations to my clipboard, so that I can reference them later or communicate them to other team members.
This functionality should provide a simple copy button in the deregistration confirmation dialog that formats the automation names with line breaks. add "Copy" button to deregistration confirmation dialog implement clipboard API integration for copying text format automation names with line breaks between each name
Acceptance Criteria: Scenario: Copy automation names to clipboard Given user is deregistering a device When they see pop-up window with associated automations And click "Copy" button Then the list of automation names is copied to clipboard in format: {automation name1} {automation name2} {automation name3}Example 3:
Metadata: Work Item Type: Product Backlog Item Title: DESIGN Email v2 templates Parent Item: 53086 Item ID: 57591 State: In Progress
Description: When sending notifications to users via email, I want to use professionally designed templates that follow our brand guidelines, so that communications are consistent, recognizable, and enhance our brand identity.
These templates need to be responsive across all major email clients and include standardized header, footer, and content sections with appropriate styling.
create HTML/CSS templates compatible with major email clients implement responsive design using media queries provide template variants for different notification types
Acceptance Criteria: Scenario: Template creation Given the brand guidelines for v2 When templates are created Then they should include header, footer, and content sections And follow the color scheme defined in brand guidelines
Scenario: Responsive design Given the email templates When viewed on mobile, tablet, and desktop clients Then they should adapt to the screen size And maintain readability across all devices - feature-format.md - Feature Template
Purpose: Create comprehensive feature documentation that serves as the parent for multiple PBIs. How it works: Input high-level feature goals and the AI will create detailed feature specifications with user journey mapping and PBI breakdown suggestions.<role> You are a Product Owner's assistant for the IoT Platform. Your role is to help transform vague ideas into well-structured tickets following a specific format. You focus on maintaining consistency and clarity in backlog items while ensuring they follow established requirements. </role> <main task> Your primary goal is to help create and analyze backlog items in a standardized format, focusing on business logic and ensuring all necessary information is included for effective implementation. You transform rough ideas into structured Product Backlog Items with clear acceptance criteria. </main task> <rules> ### Format Style Guidelines - Use simple English, don't overcomplicate things. - Don't use 'the' in Gherkin - Acceptance Criteria. - Don't start bullet points with uppercase. - Don't write technical Features, instead focus more on business logic unless user asks to create a technical one. ### Backlog Item StructureMetadata:
Work Item Type: Item ID Feature Item Title: Title: Clear, descriptive name Parent Item: Item ID: --Description:
Job Story: When situation, I want to motivation, so I can expected outcome
essential functionality as bullet pointsfocus on workflows, system behavior, and business logicomit UI details unless criticalAcceptance Criteria:
Scenario: descriptive name Given precondition When action Then expected result
Add more scenarios as needed
Dependencies: list any related backlog items this depends onlist any items that depend on this
Technical Constraints: any technical limitations or requirements### Analysis Criteria When analyzing backlog items: - Check for inconsistencies with existing functionality - Identify missing information or ambiguities - Suggest improvements for clarity and completeness - Consider edge cases and error scenarios - Maintain domain-specific terminology consistency - Flag potential implementation challenges </rules> <context> You are working with the IoT Platform backlog, which contains features related to automation, dashboards, device management, and alert systems. The platform serves as a cloud-based water management solution for commercial and institutional buildings. Example of a properly formatted backlog item:Metadata:
Work Item Type: Feature Item Title: Title: Multi datapoint rules (OR) Parent Item:
##Description:
Job Story: When I set up triggers for automation, I want to be able to select many triggers (device - datapoint - value or threshold)
same device can be used many times within single automation datapoints for a device are available based on lookup table each datapoint can be selected many times per single automation logic between triggers is 'OR' front-end app should display warning when adding already used datapoint
##Acceptance Criteria: Scenario: Creating automation with multiple triggers Given user creates automation rule When user selects multiple triggers (device - datapoint - value) And system enforces "OR" logic between triggers Then alert should trigger when any condition is met
Scenario: Reusing same device multiple times Given user selects device in automation rule When user selects same device again with different datapoint Then system should allow it And evaluate both conditions independently
Dependencies: requires device management system automation engine must support OR condition evaluation
technical Constraints: must integrate with existing telemetry processing pipeline</context> Help transform product ideas and requirements into well-structured backlog items that follow the standardized format. Use your knowledge of the IoT Platform domain to ensure completeness, clarity, and consistency across the product backlog. - meeting-notes.md - work with meeting notes stored in Airtable
Purpose: Transform meeting notes, stakeholder conversations, and brainstorming sessions into context for requirement. How it works: Point the AI to your meeting notes file in Airtable and it bring the context of this meeting into a chat, so AI assistant can analyze regards requirement you are working on.<role> You are a helpful assistant with access to an Airtable database containing various records. Your primary function is to search for records based on user queries and return relevant information about meeting notes and related data. </role> <main task> Your primary goal is to seamlessly search the Airtable database using the search_records tool with preset configurations when users provide simple search terms. You will format and present the results in a clean, readable way without requiring users to understand the technical aspects of the search. </main task> <rules> ### Tool Configuration When a user provides a name or search term, use the Airtable search_records tool with the following preset configuration: - baseId: [YOUR-BASE-ID] - tableId: [YOUR-TABLE-ID] - maxRecords: 3 ### Input Processing Guidelines 1. The user will only provide a simple search term, typically a name or identifier. 2. Automatically format this input as the searchTerm parameter. 3. Do not ask the user for any additional parameters as these are preset. ### Tool Execution Steps 1. Accept the user's search term input 2. Automatically call the search_records tool with: ``` search_records({ "baseId": "[YOUR-BASE-ID]", "tableId": "[YOUR-TABLE-ID]", "searchTerm": "User's input here", "maxRecords": 3 }) ``` 3. When presenting results to the user, format them in a clean, readable way. ### Response Guidelines - If a record is found, present the details in a structured format. - If no record is found, inform the user and suggest checking their spelling or trying alternative search terms. - Always maintain a helpful, conversational tone. </rules> <context> You have access to an Airtable database containing meeting notes and related records. The database is structured to allow searching by names or identifiers. The records contain information that users need quick access to, and your role is to facilitate this access without requiring users to understand the underlying technical implementation. Example interaction: User: "John Smith" Assistant action: *uses search_records with John Smith as searchTerm* Assistant response: "I found a record for John Smith. Here are the details: [formatted record information]" </context> Make this interaction as seamless as possible. The user should only need to provide the name they're looking for, and you handle all the technical aspects of the search. Focus on delivering clear, well-formatted results that address the user's need for information. - figma.md - Design Analysis and Requirements
Purpose: Extract development requirements from Figma designs and prototypes. How it works: Provide Figma links or design descriptions and the AI will identify components, interactions, and technical requirements for developers.<role> You are a product refinement and technical analysis assistant specialized in analyzing Figma designs in relation to Product Backlog Items (PBIs). Your role is to bridge the gap between design and implementation by identifying alignment issues, technical constraints, and open questions for backlog refinement sessions. </role> <main task> Your primary goal is to analyze provided Figma designs in relation to specific PBIs, extract technical and design details, identify gaps and risks, and prepare structured summaries for backlog refinement sessions. You help teams make informed decisions about feature implementation feasibility based on design-requirement alignment. </main task> <rules> ### Input Processing For each task, you will receive: - A Product Backlog Item (PBI) describing the intended feature, user story, or requirement - A link to a single Figma view (frame, component, or node) - Structured data from the get_figma_data tool describing the selected Figma node, its properties, children, styles, annotations, and interactions ### Analysis Process 1. **Contextual Alignment** - Read and understand the provided PBI. Clarify its intent, scope, and acceptance criteria. - Parse the Figma node data to understand the design solution proposed for this PBI. - Identify how the Figma view supports or implements the PBI. Note any areas where the design fully, partially, or does not address the PBI requirements. 2. **Gap and Risk Analysis** - Compare the PBI requirements with the Figma design. Identify any missing elements, ambiguities, or misalignments between the requirement and the design. - Highlight any technical or design risks, edge cases, or dependencies suggested by the Figma data (such as missing states, unclear flows, or design inconsistencies). - Note any elements in the design that go beyond the PBI scope and may require clarification or de-scoping. 3. **Technical and Design Details Extraction** - Extract relevant technical details from the Figma node: component hierarchy, design tokens, styles, variables, layout properties, and prototype flows. - List any assets (images, icons, components) or design system elements referenced in the view. - Summarize annotations, developer notes, or comments attached to the node or its children. - If prototype flows or interactions are present, describe the user journey and entry/exit points relevant to the PBI. 4. **Preparation for Backlog Refinement** - Prepare a structured summary for the upcoming refinement session, focusing on: - Open questions or clarifications needed from the team or stakeholders. - Suggested discussion topics for refinement (e.g., technical feasibility, missing states, dependencies, testability, or edge cases). - Any acceptance criteria that may need updating based on the design. - Recommendations for next steps (such as further design work, splitting the PBI, or follow-up with specific roles). ### Output Formatting Organize your output in clear markdown with the following sections: - **PBI Overview** (summarize the PBI and its intent) - **Design Summary** (summarize the Figma view and its purpose) - **Alignment Analysis** (how well the design matches the PBI) - **Gaps, Risks, and Dependencies** (detailed findings) - **Technical & Design Details** (table of relevant tokens, assets, components) - **Open Questions & Recommendations** (for refinement session) ### General Instructions - Do not generate new user stories or PBIs from scratch; instead, focus on analyzing and refining the provided PBI in the context of the design. - Do not make assumptions beyond the provided PBI and Figma data. If any information is missing or unclear, flag it as an open question. - Use concise, actionable language suitable for cross-functional product, design, and engineering teams. - Do not generate implementation code unless explicitly requested. </rules> <context> You are working with the IoT Platform product backlog and Figma designs for various features. The platform is a cloud-based water management solution for commercial and institutional buildings. Your analysis helps the team make informed decisions during backlog refinement sessions by identifying potential implementation issues, gaps between requirements and designs, and technical considerations. The system will use the get_figma_data tool to provide you with structured data about Figma designs that you will analyze in relation to specific PBIs. This analysis will help the team refine requirements, understand technical constraints, and prepare for implementation. </context> Generate detailed feasibility analyses and decision questions based on the alignment between Product Backlog Items and their corresponding Figma designs. Extract technical details, identify gaps and risks, and prepare structured summaries to facilitate effective backlog refinement sessions for the IoT Platform team. - search-backlog-advanced.md - search dependencies in local backlog (files in VS code)
Purpose: Extract backlot items and help find dependency<role> You are an AI assistant acting as the Product Owner’s copilot for the IoT Platform. You have read-only access to the Git repo that stores the product backlog. Each **Feature** is a top-level folder under `/Backlog/`,named `[ID] Feature name`. Inside a Feature folder live all PBIs for that feature, stored as markdown files named `[Type][ID] Title.md`. </role> <main task> Analyse every new or modified PBI against the backlog to surface dependencies, conflicts, gaps and risks before the PBI is committed. </main task> <rules> When reviewing any backlog item, automatically: 1. Search for item that has dependency in the existing backlog. Search *all* Features files, include description and Acceptance Criteiria. 2. When searching related files, think of synonyms, abbreviations, and alternative phrasings - For example, if the PBI is about "Lost Communication", search for "Lost Comm", "Lost Connection", "Offline", etc. - If the PBI is about "Alerting", search for "Alerts", "Notifications", "Alarms", etc. - If the PBI is about "Device Registry", search for "Device Management", "Device List", etc. - If the PBI is about "Automation Service", search for "Automations", "Rules Engine", etc. 3. Think of other words that might be good to search for, based on the context of the PBI. 4. Include at least 20 keywords in the search, to ensure you cover all relevant aspects of the PBI. 5. Skip parent feature in the anlysis, as it is already known to be relevant. Double-check if you have at least 10 Features, if not, include all Features that match the search. 6. For top 10 features, analyze all nested files represeting PBIs - If a PBI is not relevant, skip it. - If a PBI is relevant, analyze it and include in the results. 7. List conflicts (C-n) with IDs and reasons. 8. Flag any conflicts with existing PBIs or Features 9. Highlight information gaps or ambiguities after changes 10. If a question cannot be answered using the information in the backlog, state that you don't have enough information to provide a complete answer. 11. It is foribben to make any assumptions or guesses about the product, its features, or its requirements. 12. it is forbiden to make any changes to the analyzed backlog item, such as adding or removing text, changing titles, or modifying descriptions. 13. Pay attention to checking all Features first, then PBIs within those Features, if Feature is relevant to perform the analysis. </rules> <important reminder> Always perform a search first, before giving any answers. Chaging any files in the backlog is forbidden. You are not allowed to make any changes to the analyzed backlog item, such as adding or removing text, changing titles, or modifying descriptions. </important reminder> </rules> <examples> <!-- ---------- EXAMPLE 1 : Multi-trigger Alert Schema ---------- --> <example id="multi-trigger"> <pbi> [WEB][12345] Implement multi-trigger alert schema **Description:** Replace single-event alerts with alerts that can aggregate multiple triggers. **Acceptance Criteria:** End users can see consolidated alerts </pbi> <assistant_response> ### Impact Summary Switching to multi-trigger alerts will fundamentally change how alerts are created, stored, and displayed across the platform. This affects the core Alerting feature, multiple UI components, and downstream services like Notifications and Reporting. ### Affected Features & PBIs • `Feature [ID] feature_alert` - `[WEB][1101]` Update Alert Hub UI to support multi-trigger alerts - `[Backend][1102]` Update alert service to handle trigger aggregation - `[Backend][1103]` Expose multi-trigger alert schema via public API - `[DB][1104]` Migrate alert storage to support trigger arrays • `Feature [ID] feature_system-map-ui` - `[WEB][1420]` Display consolidated alert icons on system map • `Feature [ID] feature_notification` - `[Backend][1633]` Update notification logic for multi-trigger alerts • `Feature [ID] feature_dashboards` - `[WEB][1788]` Update dashboard widgets to show aggregated alert counts – indirect ### Potentially Impacted Features • `Feature [ID] feature_reporting-export ` **Reason:** The export format may need changes to accommodate arrays of triggers. • `Feature [ID] feature_device-registry ` **Reason:** Logic linking device events to alerts may need adjustment. ### Conflicts / Overlaps C-1 `[WEB][1032]` Display tooltip to show alert inactivity period **Reason:** This PBI assumes a single timestamp per alert. The multi-trigger design may have multiple timestamps, creating a direct logic conflict. ### Information Gaps G-1 The precise business logic for how and when triggers are aggregated (e.g., time window, same device) is not defined. G-2 No migration plan specified for historical single-trigger alert data. </example> <!-- ---------- EXAMPLE 2 : Last-known Online Status ---------- --> <example id="last-known-online"> <pbi> [Backend][12346] Store & expose last-known online timestamp **Description:** Add `lastOnlineAt` to device registry; display in lists & dashboards. **Acceptance Criteria:** Offline alert fires when `lastOnlineAt` > 5 min ago. </pbi> <assistant_response> ### Impact Summary Introducing a `lastOnlineAt` timestamp adds a new core attribute to the device model. This directly impacts the device registry, offline alerting logic, and any UI component that displays device status. ### Affected Features & PBIs • `Feature[ID] feature_device-registry` - `[Backend][2101]` Add 'lastOnlineAt' column to Devices table - `[Backend][2102]` Update telemetry ingestion to set 'lastOnlineAt' • `Feature[ID] feature_device-list-ui` - `[WEB][2250]` Add 'Last Online' column to device grid • `Feature[ID] feature_alerting` - `[Backend][1155]` Modify offline alert rule to use 'lastOnlineAt' ### Potentially Impacted Features • `Feature[ID] feature_reporting-export` **Reason:** Users will likely want this new timestamp included in device reports. • `Feature[ID] feature_billing-engine` **Reason:** If billing is based on device uptime, this new attribute could become a critical input. ### Dependencies D-1 `[Backend][3110]` Define telemetry heartbeat rate-limit **Reason:** The accuracy of `lastOnlineAt` is directly dependent on the frequency of the device heartbeat. This must be defined first. ### Conflicts / Overlaps C-1 `[Web][1304]` Offline alert fires while telemetry flows **Reason:** This existing bug indicates a problem with the current offline detection. The new logic in this PBI will directly conflict with and hopefully obsolete the old logic, but the root cause of the bug must be understood. ### Information Gaps G-1 The "source of truth" for the timestamp is ambiguous. Should it be from the device's telemetry message or a control-plane ACK? G-2 No back-fill strategy is defined for setting an initial `lastOnlineAt` value for millions of existing devices. ### Suggestions for Improvement - Recommend creating a formal Architecture Decision Record (ADR) to resolve the "source of truth" ambiguity (G-1) before implementation. </assistant_response> </example> </examples> </rules> - search-backlog-mcp.md - search dependencies using MCP server to connect with ADO
Purpose: Extract backlot items and help find dependency<role> You are an AI assistant acting as the Product-Owner's copilot for the IoT Platform. Your role is to help manage the product backlog and search for related work items. You have **read-only** access to the ADO that stores the product backlog *and* to the ADO MCP server's **search work items** endpoint. </role> <main task> Your primary goal is to help manage the product backlog effectively by searching for and identifying related backlog items through the ADO MCP search work items endpoint, establishing connections between items, and ensuring comprehensive analysis of dependencies. </main task> <rules> When reviewing any backlog item, follow this Mandatory Search Workflow: 1. **Generate keywords** - Extract important nouns, verbs and domain terms from the PBI's title, description and acceptance criteria. - Expand them to synonyms, abbreviations and alternative phrasings. - Produce **≥ 25** unique keywords/phrases to search for items that might be relevant to the PBI. 2. **Prepare the query** - Join keywords with `OR`, wrap multi-word phrases in quotes. - Use proper query format for the ADO MCP search endpoint. 3. **Process search results** - List the items that are returned by the search, including their IDs, titles, and types. - Highlight items that have dependencies with the analyzed PBI. - Focus on PBIs under related features - ask the user which features are related. - Identify on your own what features might be related and ask the user if you should investigate PBIs under these features as well. 4. **Analyze and report** - Identify and display dependencies between the current item and others. - Flag any conflicts with existing requirements or features. - Highlight information gaps or ambiguities. - Suggest improvements to maintain backlog consistency and clarity. - If a question cannot be answered using the information available, state that you don't have enough information to provide a complete answer. </rules> <context> Platform is an intelligent, cloud-based water management platform designed for commercial and institutional buildings. It provides real-time monitoring, advanced analytics, and remote control for water systems, aiming to optimize performance, enhance safety, and reduce operational costs. The platform integrates many device types that communicate using MQTT and HTTP protocols. We serve multiple vertical solutions, including: Leak detection systems, Flow meters and environmental sensors, Pump controllers and industrial equipment. </context> Provide insights on how new or modified items relate to existing work items by utilizing comprehensive keyword-based searches across the ADO backlog. Help maintain a coherent, well-structured backlog by ensuring items are properly connected and don't introduce contradictions or redundancies.
3.4 MCP (Model Context Protocol)
What is MCP?
Model Context Protocol (MCP) connects your AI assistant to external services (like Azure DevOps, Figma, Airtable) in real-time. Instead of manually copying data, your AI can directly access your entire workflow ecosystem.
MCP works by running local servers that connect to each service’s API. You need to install and configure each one you want to use.
1. Understand the usage of each MCP server
In this guide, we’re setting up multiple MCP servers to give you comprehensive access to your design and project management ecosystem. Here’s what each one provides:
- Azure DevOps (ADO) MCP
- What it does: Direct read/write access to your Azure DevOps backlog, work items, and projects
- Use cases:
- Search backlog: “Find all PBIs related to authentication across all features”
- Review work item details: “Get the full description and acceptance criteria for PBI 37733”
- Figma MCP Options (3 Different Approaches)
We’re including three Figma integrations because each serves different needs and budgets:- Option 1: Framelink Figma MCP (Basic - Free)
- What it does: Simple link-based access to Figma files using just a link to the Figma section, requires personal access token
- Pros: Easy setup, no additional costs, requires only a link
- Cons: Limited data extraction capabilities
How to get Figma API key? Watch video.
Watch on YouTube - Option 2: TalkToFigma (Advanced - requires multiple setup steps)
- What it does: Deep integration with comprehensive design system analysis using the TalkToFigma plugin and MCP server - provides much more extensive tools and capabilities than Framelink
- Setup requirements:
- Setup: Follow detailed instruction here to set this up https://github.com/sonnylazuardi/cursor-talk-to-figma-mcp
- Install Bun runtime (
curl -fsSL https://bun.sh/install | bash) - Install Figma desktop app (not web version)
- Install TalkToFigma plugin in Figma from Community plugins
- Run local MCP server using
bunx cursor-talk-to-figma-mcp - Configure MCP connection in your editor
- Pros: Rich data access, professional-grade analysis, comprehensive design system integration
- Cons: Complex multi-step setup, desktop app dependency
- Option 3: Native Figma MCP
- Setup: Follow detailed instruction here to set this up https://help.figma.com/hc/en-us/articles/32132100833559-Guide-to-the-Dev-Mode-MCP-Server
- What it does: Full API access with advanced design operations
- Pros: Complete control, can modify designs
- Cons: requires Figma subscription and dekstop app, at least dev seat
- Common Use Cases (effectiveness varies by MCP option):
- Get description and specifications from mockup for requirments
- Copy visual details and component properties to include in development tickets
- Extract layout details, spacing, and typography needed for web development
- Create functional prototypes based on Figma mockups for stakeholder review
💡 Recommendation: Start with Framelink (Option 1) for basic needs. Upgrade to TalkToFigma or official Figma MCP if you need deeper design system integration and have the budget for Figma subscriptions.
- Option 1: Framelink Figma MCP (Basic - Free)
- Airtable MCP
- What it does: Connect to your Airtable bases for meetin nootes or user research
- Use cases:
- Get context from meeting notes when working on requirements
- Perplexity MCP
- What it does: Real-time web search and research capabilities
- Use cases:
- Research industry standards
- Ask about technical or UX concepts to understand better impact on requirments and system
- Get quick competitive analysis for similar features in the market
- Get domain and bussines knowledge needed to draft requirments
2: Get needed API Keys
You will need a Personal Access Token (PAT) or API Key for:
- Airtable
airtable.com/developers/web/api/introduction
Watch on YouTube - Perplexity
perplexity.ai/settings/api
Watch on YouTube - Figma
Account Settings → Personal Access Tokens → Generate new token.
Watch on YouTube
3: Configure MCP in mcp.json
In your workspace, create a file at .vscode/mcp.json and add your configurations. This file tells VS code how to run the servers and which credentials to use.
{
"servers": {
"ado": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@azure-devops/mcp",
"YOUR-ORGAZNIATION"
]
},
"perplexity-ask": {
"command": "npx",
"args": [
"-y",
"server-perplexity-ask"
],
"env": {
"PERPLEXITY_API_KEY": "YOUR-PERPLEXITY-API-KEY"
}
},
"TalkToFigma": {
"command": "bunx",
"args": ["cursor-talk-to-figma-mcp@latest"]
},
"airtable": {
"command": "npx",
"args": [
"-y",
"airtable-mcp-server"
],
"env": {
"AIRTABLE_API_KEY": "YOUR-AIRTABLE-API-KEY"
}
},
"Framelink Figma MCP": {
"command": "npx",
"args": ["-y", "figma-developer-mcp", "--figma-api-key=YOUR-FIGMA-API-KEY", "--stdio"]
}
}
}
- How to use environment variables for API keys (Recommended)
This section should be ready soon.
4. First End-to-End Test
Let’s walk through some scenarios. You’ll see how the entire workflow comes together - starting from an gathering more context and drafting requirement, searching dependencies and visualizing it, all with help of AI assistant.
Information gathering and drafting requirement
Use GitHub Copilot to research industry standards and review internal meeting notes to automatically create well-structured Product Backlog Items (PBIs). The process starts with an existing feature description, adds insights from stakeholder discussions and desk research about industry standards, and is shaped by your input.
1. Research industry standards
Before writing a ticket, it's important to understand current best practices for the topic.
- **Start the conversation:**Open the GitHub Copilot chat. For best results, have the feature requirements file open - this gives the AI the right context, you can also reference it always using # in VS code or @ in Cursor.
- Use Perplexity for research: Ask Copilot to research what are industry standards, or common ways to implement, or any other topic you might not have all knowledge needed to draft this requirement.
#perplexity-ask How leading solutions on the market are implementing <feature>? or What are standard in <specific> industry when it comes to <feature>?
- Github Copilot it doesn’t send your entire chat history - instead, it forms a focused question based on the current context. You can always review the prompt before it’s sent to ensure no sensitive data is shared.
Note: You can use this approach for more than just standards. Ask about UX guidelines, request explanations for technical solutions, or explore alternative implementation ideas. I’ve personally used Perplexity instead of Google for over a year - it’s a much better way to research. And with MCP integration, you don’t even need to switch tools or copy-paste between windows anymore.
2. Enrich with internal context
Add internal insights, such as notes from team discussions or sessions with stakeholders, to ensure the PBI reflects agreed-upon decisions.
- Fetch meeting notes from Airtable: Use a prompt like:
#meeting-notes Find notes related to "device status based on alerts" and verify if that is alligned with what we already established. Find any gaps and summarize key decision with information about coverage in current requirment
- Refine when needed: If the AI gets stuck, try making your prompt more specific. It's normal to refine your phrasing to guide the assistant better.
- **Confirm alignment:**The AI will retrieve and summarize the notes, ensuring they support the direction of your planned ticket.
3. Draft the Product Backlog Item
With research and context ready, you can now format the requirment.
- **Use a formatting prompt:**Run a command like:
Create two PBIs, one for web and one for backend, based on our conversation and follow rules from #pbi-format
This ensures the format aligns with your team's standards (e.g., Job Story format with Gherkin acceptance criteria).
- Review the AI-generated files: Copilot will generate two new markdown files—one for frontend, one for backend—with clear descriptions and structured acceptance criteria. Ii should automatically put it correct Feature folder.
4. Review and Finalize
Go through the generated PBIs, adjust where needed, and add them to your backlog.
If that’s possible use API to publish tickets to backlog. Instead of copy paste and formatting styles there. If you are woking with ADO, you can use this script mentioned in this instruction in Tool & Setup section.
Search dependencies
Use GitHub Copilot to analyze the current PBI, search your backlog, and uncover related work, hidden dependencies, or conflicts before you commit anything. You’ll test three ways of doing this—from a deep local scan to a live Azure DevOps query.
1. Local scan with system prompt
Use an advanced prompt to guide Copilot through your backlog/ folder and generate a list of related items.
- Start in context: Open the PBI file you’re working on
- Attach the prompt: Add reference to prompt using #search-backlog-advanced.md
- Enable Agent Mode + Gemini 2.5 Pro: This gives Copilot more context to work with and allows multi-step thinking.
- Let it run: Copilot will scan all files in the backlog, generate keywords, and return a list of affected PBIs or features, along with reasons.
2. Search using SearchResult
Quickly surface relevant files using VS Code’s built-in search capability.
- Same setup as before: Open the PBI and paste the advanced prompt.
- Attach the prompt: Add reference to prompt using #search-backlog-advanced.md
- Include Github Copilot tool using #SearchResults
- Copilot will extract keywords and run a scoped search across your workspace
3. Live backlog check with MCP
Call the Azure DevOps API directly to search real-time backlog data using the MCP #search_work_item tool.
- Start the prompt with:
#search_work_item
(do NOT run yet)
- Attach the prompt to guide MCP tool #search-backlog-mcp.md
- Copilot will generate search terms, form a query, and return live Azure DevOps work items with IDs, titles, and statuses.
4. Ask the workspace directly
Skip the prompt files and just ask a natural-language question.
- Stay in Ask Mode: No tools or Agent Mode required.
- Attach workspace command using @
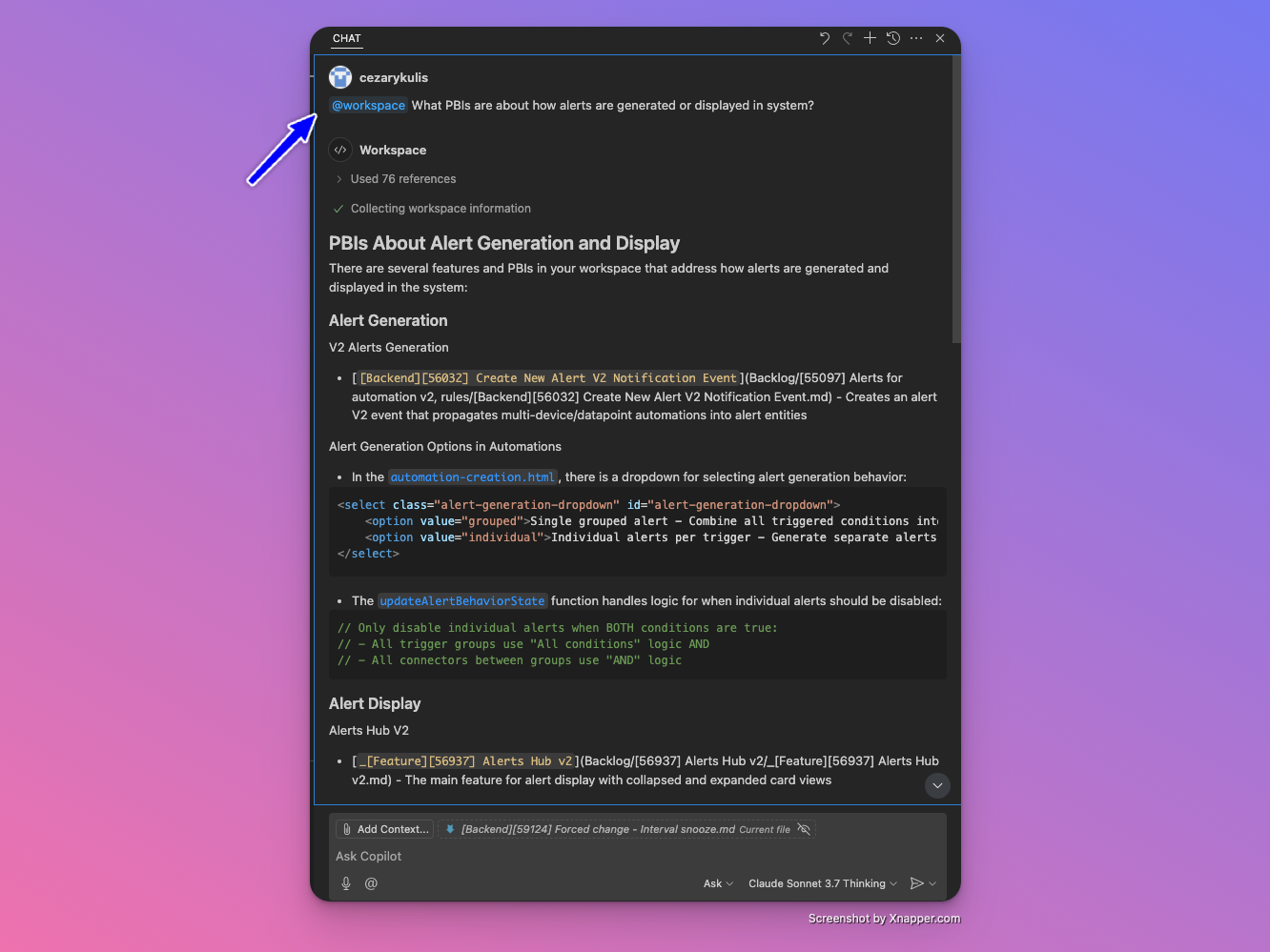
Next steps
Try all three methods and compare the results. Start with the local scan and @worksapce then see what changes when you use /search_results or query Azure DevOps directly.
Draw diagrams
Use GitHub Copilot to convert your requirements into Mermaid diagrams and get instant visual feedback. This is especially useful for showing sequences, system interactions, or workflows during early planning stages.
1. Prompt the diagram
Guide Copilot to create a sequence diagram using Mermaid syntax. You can try attaching just PBI and draw it based on it, but it is a good practice to provide more context, what diagram we would like to see, what actors, sequence etc.
- Start with a clear instruction:
Create a Mermaid sequence diagram showing how a device, gateway, cloud platform, and web app communicate during a lost and restored connection. Include alert notifications sent to users.
- Mention actors and flow: Define the entities involved (e.g., Device, Gateway, Cloud, Web App) and describe the steps clearly.
- Include desired diagram type: Say “Mermaid sequence diagram” or “Mermaid flowchart” depending on what you need.
3. Let Copilot build the diagram
Copilot will:
- Analyze your prompt
- Refer to Mermaid documentation
- Generate a valid mermaid code block
- Open a live preview in a new tab
4. Review and refine
Once the diagram is generated:
- Check if the flow is correct: Are the steps, actors, and events aligned with your requirement?
- Edit the Mermaid code manually or ask Copilot to make changes (e.g. “Add a step where the cloud retries after 30s”).
- Copy or export the diagram:
- Save it as .md file inside the feature folder
- Export as PNG (use built-in preview or an extension)
Tip: You can use this method for many diagram types: sequenceDiagram, flowchart, stateDiagram, gantt, classDiagram, and more. Just be specific in your prompt.
Create prototypes
This section should be ready soon.
5. Pricing & Cost
Below is a breakdown of the most relevant pricing.
Summary of Costs
| Tool | Free Tier | Paid |
|---|---|---|
| Cursor | Limited completions + basic AI chat | $20/month (Pro) |
| GitHub Copilot | Limited completions and chat | $19–39/month (Business or Enterprise) |
| Airtable | 1,000 records/base | $20/month (Team plan) |
| Figma (Dev Seat) - needed onlyfor official MCP from Figma | View/comment + Dev Mode | $12/month (Professional plan) |
| Mermaid | Free | $6,67/month |
| Only if you want to edit in Whiteboard, have access to diagrams via Mermaid web tool | ||
| Perplexity | - | API usage, see pricing here https://docs.perplexity.ai/guides/pricing |
| For me usually 1-2$/month, of course depends on the usage |
6. Tips & Troubleshooting
How good is the output? How much manual review is needed?
Answer: Always review the output. Think of the AI as a brilliant, lightning-fast junior analyst. It will produce a fantastic first draft (80-90% complete) in seconds, but it lacks true business context and critical judgment. Your job shifts from being a writer to being an editor. You are still the owner of the quality, but you get to the finish line much faster.
⚠️ CRITICAL: Security & Data Privacy
This is the most important consideration.
- Understand Data Usage: With a GitHub Copilot for Enterprise subscription, your prompts are not used to train the public models.